
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 2020년 정보처리기사 4회
- hackerrank
- 필기
- 항해99
- Real MySQL
- sqldeveloper
- 뇌정리
- 코드숨
- If
- Python
- 책리뷰
- 미니프로젝트
- 정보처리기사
- 서평
- Jackson
- algorithms
- 2020년 제4회 정보처리기사 필기 문제 분석
- java
- 함수형 코딩
- 성적프로그램
- LeetCode
- git
- post
- 알고리즘
- jsp
- 2020년 일정
- Til
- 주간회고
- 회고
- 스터디
- Today
- Total
조컴퓨터
200914 SW활용 02 - 데이터베이스 생성과 삭제 / SQL활용 02 - SQL 제약조건 본문
Database Oracle SQL Developer 연결하고 시작하기
1) 새로 만들기

2) Oracle 접속하기
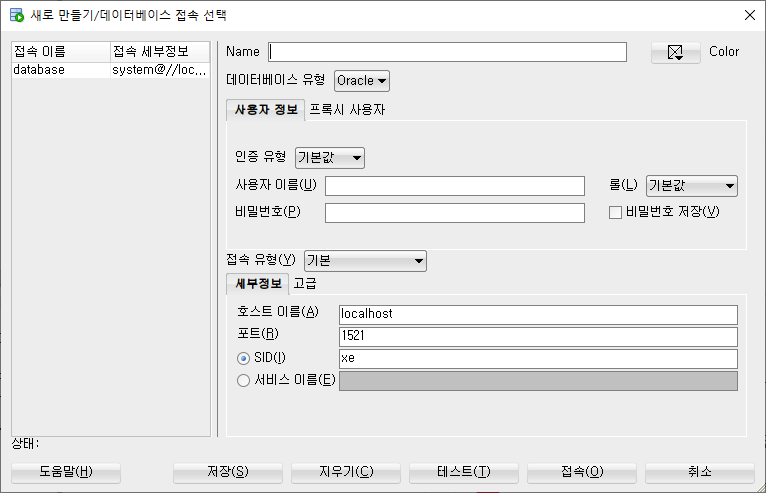
Name : database
사용자 이름 : system
비밀번호 : 1234
호스트 이름 : localhost
포트 : 1521
SID : xe
3) 접속하기
성적 테이블
C:/java0812/database/20200914_SQL기초.sql
-- 성적테이블 삭제
drop table sungjuk;
-- 성적테이블 생성
create table sungjuk(
uname varchar(50) not null
, kor int not null
, eng int not null
, mat int not null
, tot int null --총점
, aver int null --평균
);
-- 행추가
insert into sungjuk(uname,kor,eng,mat)
values ('홍길동',50,60,30);
insert into sungjuk(uname,kor,eng,mat)
values ('무궁화',30,30,40);
insert into sungjuk(uname,kor,eng,mat)
values ('진달래',90,90,20);
insert into sungjuk(uname,kor,eng,mat)
values ('개나리',100,60,30);
insert into sungjuk(uname,kor,eng,mat)
values ('라일락',30,80,40);
insert into sungjuk(uname,kor,eng,mat)
values ('봉선화',80,80,20);
insert into sungjuk(uname,kor,eng,mat)
values ('대한민국',10,65,35);
insert into sungjuk(uname,kor,eng,mat)
values ('해바라기',30,80,40);
insert into sungjuk(uname,kor,eng,mat)
values ('나팔꽃',30,80,20);
insert into sungjuk(uname,kor,eng,mat)
values ('대한민국',100,100,100);
-- 명령어 완료
commit;
※ commit 처리는 필수이다.
예제1) 전체 레코드 갯수
select count(*) from sungjuk;
결과값

예제2) 전체 레코드 조회
select * from sungjuk;
결과값

tot, aver값은 update를 통해 보충해 주어야 한다.
where 조건절
- 조건에 만족하는 레코드만 대상으로 조회, 수정, 삭제
select * from sungjuk;
예제3) 국어 점수가 50점 이상인 행을 조회하시오.
select uname, kor
from sungjuk
where kor>=50;
결과값
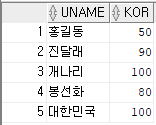
예제4) 영어 점수가 50점 미만인 행을 조회하시오.
select uname, kor, eng, mat
from sungjuk
where eng<50;
결과값

예제5) 이름이 '대한민국'인 행을 조회(출력)하시오.
select uname, kor, eng, mat
from sungjuk
where uname='대한민국';
결과값

예제6) 이름이 '대한민국'이 아닌 행을 조회하시오.
select uname, kor, eng, mat
from sungjuk
where uname!='대한민국';
결과값

예제7) 국어, 영어, 수학 세 과목의 점수가 모두 90점 이상인 행을 조회하시오.
select uname, kor, eng, mat
from sungjuk
where kor>=90 and eng>=90 and mat>=90;
결과값

예제8) 국어, 영어, 수학 세 과목 중에서 한 과목이라도 40점 미만인 행을 조회하시오.
select uname, kor, eng, mat
from sungjuk
where kor<40 or eng<40 or mat<40;
결과값

예제9) 국어 점수가 80 ~ 89점 사이의 행을 조회하시오.
select uname, kor
from sungjuk
where kor>=80 and kor<=89;
결과값

between A and B
- A에서부터 B까지
예시)
select *
from sungjuk
where kor between 80 and 89;
결과값

예제10) 이름이 '무궁화', '봉선화'를 조회하시오.
① where 조건절
select *
from sungjuk
where uname='무궁화' or uname='봉선화';
결과값

② in 연산자
- 문자열 목록에서 찾기
select *
from sungjuk
where uname in ('무궁화', '봉선화');
결과값

예제11) 국어, 영어, 수학 세 과목 모두 100점이 아닌 행을 조회하시오.
select *
from sungjuk
where not (kor=100 and eng=100 and mat=100);
결과값

예제12) 세 과목 중에서 한 과목이라도 100점인 행을 조회하시오.
select uname, kor, eng, mat
from sungjuk
where kor=100 or eng=100 or mat=100;
결과값

예제13) 이름이 '대한민국'인 행의 평균을 구하시오.
① update ~ set 구문
update sungjuk
set aver=(kor+eng+mat)/3
where uname='대한민국';
② select 결과
select * from sungjuk;
결과값

※ uname='대한민국' 행의 aver값에 변화가 있음을 확인할 수 있다.
예제14) 평균 칼럼이 비어있는 행을 조회하시오.
select *
from sungjuk
where aver=null; -- 틀림
-- null값 조회
select *
from sungjuk
where aver is null;
결과값

참조) null이 아닌 행 조회
select *
from sungjuk
where aver is not null;
결과값

※ 예제13에서 aver값의 update를 진행했기 때문에 uname='대한민국'의 aver값이 null이 아님을 확인할 수 있다.
like 연산자
- 문자열 데이터에서 비슷한 유형을 검색할 때
- % 글자 갯수와 상관이 없음
- _ 글자 갯수까지 일치해야 함
예제15) 이름에서 '홍'으로 시작하는 이름을 조회하시오. (홍씨)
select *
from sungjuk
where uname like '홍%';
결과값

예제16) 이름에서 '화'로 끝나는 이름을 조회하시오.
select *
from sungjuk
where uname like '%화';
결과값

예제17) 이름에서 '나' 글자가 있는 이름을 조회하시오.
select *
from sungjuk
where uname like '%나%';
결과값

예제18) 두 글자 이름에서 '화'로 끝나는 이름을 조회하시오.
select uname
from sungjuk
where uname like '_화';
결과값

※ 없다.
Sort 정렬
- 오름차순 asc 기본값, 생략가능
- 내림차순 desc
- 형식) order by 칼럼1, 칼럼2, 칼럼3, ~~
예제19) 전체 레코드를 이름순으로 정렬해서 조회하시오.
① 오름차순 정렬. asc 생략 가능
select *
from sungjuk
order by uname;
결과값

② 오름차순 정렬
select *
from sungjuk
order by uname asc;
결과값

③ 내림차순 정렬
select *
from sungjuk
order by uname desc; --내림차순 정렬
결과값

예제20) 국어 점수순으로 정렬해서 조회하시오.
select *
from sungjuk
order by kor;
결과값

① 1차 정렬 : 국어 점수순으로 정렬
select *
from sungjuk
order by kor, uname desc;
결과값

② 2차 정렬 : 국어 점수가 같다면 이름을 기준으로 내림차순 정렬
select *
from sungjuk
order by kor, eng, mat;
결과값

※ kor값 기준으로 같은 점수끼리 묶고, 이 순서로 mat값 기준으로 같은 점수끼리 묶는다. mat값도 동일하다.
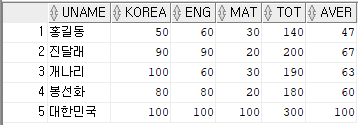
예제21) 모든 데이터의 총점과 평균을 조회하시오.
① update ~ set 구문
update sungjuk
set tot=kor+eng+mat, aver=(kor+eng+mat)/3
where tot is null or aver is null;
② select 결과
select *
from sungjuk;
결과값

※ uname='대한민국'의 aver값을 제외한 비어 있던 모든 칼럼이 채워졌다.
예제22) 평균이 50점 이상인 행을 조회하시오.
select *
from sungjuk
where aver>=50
order by uname;
select *
from sungjuk
order by uname
where aver>=50; --에러
결과값

※ where 조건절 뒤에 order by절이 와야 한다. 뒤바뀌면 오류이다.
테이블의 구조 수정
1) 칼럼 추가
형식) alter table table명 add (칼럼명 데이터타입);
-- DCL DDL DML //DDL 명령어
예제23) music 칼럼을 추가하시오.
alter table sungjuk add (music int null);
결과값

2) 칼럼명 수정
형식) alter table table명 rename column 원래칼럼명 to 바꿀칼럼명;
예제24) 국어 칼럼 kor를 korea 칼럼으로 수정하시오.
alter table sungjuk
rename column kor to korea;
결과값

3) 칼럼 데이터 타입 수정
형식) alter table table명 modify (칼럼명 데이터타입);
예제25) music 칼럼의 자료형을 varchar로 수정하시오.
-- ORA-01451: column to be modified to NULL cannot be modified to NULL
alter table sungjuk modify(music varchar(5) null);
alter table sungjuk modify (music varchar(5));
결과값

4) 칼럼 삭제
형식) alter table table명 drop(칼럼명);
예제26) music 칼럼을 삭제하시오.
① alter 삭제
alter table sungjuk drop(music);
② select 결과
select * from sungjuk;
결과값

※ kor 칼럼의 이름은 korea로 수정되었고, music 칼럼은 있었다가 삭제되었다.
as 칼럼명 임시 변경 및 부여
예시1) uname as irum
select uname as irum
from sungjuk;
결과값

예시2) uname as irum, korea as kuk, eng as english, mat as mathmatics
select uname as irum, korea as kuk, eng as english, mat as mathmatics
from sungjuk;
결과값

예시3) as 생략 가능
select uname irum, korea kuk, eng english, mat mathmatics
from sungjuk; --as 생략가능
결과값

예제27) 전체 레코드의 갯수를 조회하시오.
① select count(*) 결과
select count(*) from sungjuk;
결과값

② as cnt
select count(*) as cnt from sungjuk;
결과값

③ as 생략 가능
select count(*) cnt from sungjuk; --as 생략가능
결과값

commit 명령어 완료
rollback 명령어 취소
- SQL Developer 툴에서 자동커밋을 설정해 놓을 수 있다.
- 도구 → 환경설정 → 데이터베이스 → 객체 뷰어 → 자동커밋설정
예제28) 국어 점수 50점 미만 행을 삭제하시오.
① delete 삭제 (먼저 국어 점수 50점 이상 행을 삭제해 보자)
delete from sungjuk
where korea>50;
select * from sungjuk;
결과값

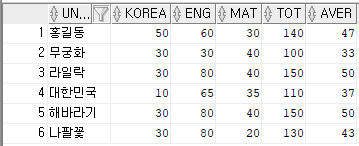
② rollback 명령어 취소
rollback; --위에서 삭제한 행이 다시 원상 복구됨
select * from sungjuk;
결과값


③ delete 삭제 (제대로 국어 점수 50점 미만 행을 삭제하자)
delete from sungjuk
where korea<50;
select * from sungjuk;
결과값

자료형
1) 문자열
2) 숫자형
3) 날짜형
database에서는 이렇게 세 가지가 중요하다.
자료형
문자열 : varchar 가변형, char 고정형
예시) varchar(5) 'SKY' -- 두 칸을 없애는 것이 가변형
char(5) 'SKY' -- 두 칸이 비워져 있는 것을 기억하는 것이 고정형
성적 테이블
-- 성적 테이블 삭제
drop table sungjuk;
-- 성적 테이블 생성
create table sungjuk(
sno int not null --일련번호
, uname varchar(30) not null
, kor int not null --, kor int 기본이 null
, eng int not null
, mat int not null
, aver int null
, addr varchar(50) --주소
, wdate date --년월일시분초
);
일련번호 자동 부여 (시퀀스 생성)
형식) 시퀀스 생성
create sequence 시퀀스명
시퀀스 삭제
drop sequence 시퀀스명
예시) sungjuk 테이블에서 사용할 시퀀스를 생성하시오.
create sequence sungjuk_seq;
-- 시퀀스 삭제
drop sequence sungjuk_seq;
결과값
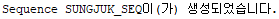
sysdate : 현재 시스템의 날짜 정보
행 추가
형식) insert into sungjuk(sno, uname, kor, eng, mat, addr, wdate)
values(1, '솔데스크', 90, 85, 95, 'Seoul', sysdate);
행 추가 확인
형식) select * from sungjuk;
행 삭제
형식) delete from sungjuk;
예시) 행 추가 (시퀀스를 이용한 일련번호 부여)
insert into sungjuk(sno, uname, kor, eng, mat, addr, wdate)
values(sungjuk_seq.nextval, '솔데스크', 90, 85, 95, 'Seoul', sysdate);
insert into sungjuk(sno,uname,kor,eng,mat,addr,wdate)
values(sungjuk_seq.nextval,'무궁화',40,50,20,'Seoul',sysdate);
insert into sungjuk(sno,uname,kor,eng,mat,addr,wdate)
values(sungjuk_seq.nextval,'진달래',90,50,90,'Jeju',sysdate);
insert into sungjuk(sno,uname,kor,eng,mat,addr,wdate)
values(sungjuk_seq.nextval,'개나리',20,50,20,'Jeju',sysdate);
insert into sungjuk(sno,uname,kor,eng,mat,addr,wdate)
values(sungjuk_seq.nextval,'봉선화',90,90,90,'Seoul',sysdate);
insert into sungjuk(sno,uname,kor,eng,mat,addr,wdate)
values(sungjuk_seq.nextval,'나팔꽃',50,50,90,'Suwon',sysdate);
insert into sungjuk(sno,uname,kor,eng,mat,addr,wdate)
values(sungjuk_seq.nextval,'선인장',70,50,20,'Seoul',sysdate);
insert into sungjuk(sno,uname,kor,eng,mat,addr,wdate)
values(sungjuk_seq.nextval,'소나무',90,60,90,'Busan',sysdate);
insert into sungjuk(sno,uname,kor,eng,mat,addr,wdate)
values(sungjuk_seq.nextval,'참나무',20,20,20,'Jeju',sysdate);
insert into sungjuk(sno,uname,kor,eng,mat,addr,wdate)
values(sungjuk_seq.nextval,'홍길동',90,90,90,'Suwon',sysdate);
insert into sungjuk(sno,uname,kor,eng,mat,addr,wdate)
values(sungjuk_seq.nextval,'무궁화',80,80,90,'Suwon',sysdate);
전체 레코드 갯수 조회
select count(*) from sungjuk;
commit;
결과값

예제29) 이름이 '무궁화'인 행을 조회하시오.
select *
from sungjuk
where uname='무궁화';
결과값

예제30) 주소가 'Seoul'인 행을 조회하시오.
select *
from sungjuk
where addr='Seoul';
결과값

예제31) 주소가 'Seoul'인 레코드만 평균을 구하시오.
① update ~ set 구문
update sungjuk
set aver=(kor+eng+mat)/3
where addr='Seoul';
② select 결과
select * from sungjuk;
결과값

※ where 조건절에서 찾고자 하는 'Seoul'값을 설정하고, set절에서 구하고자 하는 aver값을 계산한다.
예제32) 이름이 '개나리', '라일락', '진달래'인 행을 검색하시오.
select *
from sungjuk
where uname='개나리' or uname='라일락' or uname='진달래';
결과값

예제33) 주소가 'Seoul', 'Jeju'이면서 이름에 '나' 글자가 포함되어 있는 레코드를 조회하시오.
select *
from sungjuk
where (addr='Seoul' or addr='Jeju') and uname like '%나%';
--where addr in('Seoul', 'Jeju') and uname like '%나%';
결과값

예제34) 주소별로 정렬하고, 주소가 같으면 이름순으로 정렬해서 조회하시오.
(단, 평균이 50점 이상인 레코드만 대상)
① update ~ set 구문
update sungjuk
set aver=(kor+eng+mat)/3
where aver is null;
② select 결과
select *
from sungjuk
where aver>=50
order by addr, uname;
결과값

※ addr값끼리 묶인 후, 그 안에서 uname값이 오름차순으로 묶여서 출력된다.
-- sno를 기반으로 한 삭제
① delete 삭제
delete from sungjuk
where sno=1;
② select 삭제
select * from sungjuk;
결과값

※ sno=1이 삭제된 상태로 출력된다.
예제35) 서울에 사는 학생들 중에서 평균이 50점 이상인 사람이 몇 명인지 조회하시오.
① select count(*) ~ where 조건절
select count(*)
from sungjuk
where addr='Seoul' and aver>=50;
결과값

② as cnt
select count(*)
from sungjuk
where addr='Seoul' and aver>=50;
결과값

오라클 집계 함수
- 행 갯수 (null값은 대상에서 제외)
형식) select count(uname) from sungjuk;
- 전체 행 갯수
형식) select count(*) from sungjuk;
예시)
select count(*) --행갯수
, sum(kor) --국어 점수 합계
, avg(eng) --영어 점수 평균
, max(mat) --수학 점수 최대값
, min(aver) --평균 점수 최소값
from sungjuk;
결과값

select count(*)
, sum(kor)
, round(avg(eng), 2) --반올림해서 소수점 둘째 자리
, max(mat)
, min(aver)
from sungjuk;
결과값

select count(*) as cnt
, sum(kor) as kor_hap
, round(avg(eng), 2) as eng_avg
, max(mat) as mat_max
, min(aver) as aver_min
from sungjuk; --as 생략가능
결과값

예제36) 서울, 제주에 사는 학생들의 국영수 세 과목의 평균값을 출력하시오.
(단, 반올림하고 소수점은 표시하지 마시오)
① where 조건절
select avg(kor), avg(eng), avg(mat)
from sungjuk
where addr in ('Seoul', 'Jeju');
결과값

② round(avg(칼럼명1), 0) as 칼럼명2
select round(avg(kor),0) as kor_avg
, round(avg(eng),0) as eng_avg
, round(avg(mat),0) as mat_avg
from sungjuk
where addr in ('Seoul', 'Jeju');
결과값

'자바 웹개발자 과정 > Database' 카테고리의 다른 글
| 201016 Database Procedure (0) | 2020.10.18 |
|---|---|
| 200916 SQL활용 04 - SQL View와 Join Ⅰ (0) | 2020.09.17 |
| 200915 SQL활용 03 - SQL연습문제 (0) | 2020.09.15 |
| 200911 SW활용 01 - Oracle DB / SQL활용 01 - SQL Developer (0) | 2020.09.14 |



